
Rebelle.com
Rebelle ist nicht nur ein klassischer Online-Shop, sondern auch ein Marktplatz für gebrauchte Luxus-Designermode. Jeder kann hier seine Designerstücke einstellen, sei es in deutscher, italienischer, englischer, französischer oder niederländischer Sprache.
Dementsprechend gibt es Millionen von Produktseiten, die jedoch einen sehr hohen Turnover haben. Denn jede Produktdetailseite stellt ein Unikat dar, jedes Produkt gibt es nur einmal. Infolgedessen sind Produkte verfügbar und auch wieder ausverkauft – in rasanter Geschwindigkeit.
Doch wie kann diese Masse an kurzlebigen Seiten in fünf Sprachen SEO-seitig gemanagt werden? Gemeinsam mit WEVENTURE wurden Manahmen erarbeitet, die Klarheit in die Struktur bringen und Duplicate Content vermeiden sollen.
Rebelle setzte von Anfang an auf modernste Technologien und den Schwerpunkt auf gute UX und UI. Die Website ist programmiert als Single-Page-Application (SPA) und basiert dementsprechend auf Javascript. Gehostet wird sie in der Google Cloud. SPAs liegen derzeit sehr im Trend, da sie schlanker und einfacher in der Programmierung sind als klassische HTML- & CSS-Lösungen. Allerdings bringen SPAs auch einige Probleme mit sich, vor allem, wenn es um SEO geht. URLs müssen künstlich „erstellt“ werden, sogenannte „Virtual Page Views“. Dabei wird bei Rebelle jede URL in die entsprechende Sprache übersetzt, Canonical-Tags und Hreflang-Tags werden eingesetzt. Genau dieser Vorgang ist sehr wichtig, um Duplicate Content zu vermeiden. Bei Rebelle sind so einige Probleme entstanden, vor allem bei der Masse an Produktseiten. Duplicate Content entstand und belastete damit das Crawl-Budget.
Besonderheiten bei Rebelle:

Ein Blick in die Search Console reichte aus, um festzustellen, dass es eine Menge Duplicate Content gibt. Google sucht sich hier selbst eine kanonische Seite aus. Das Unternehmen verliert somit die Kontrolle darüber, welche Seiten faktisch im Index auftauchen bzw. ranken.
Interner Duplicate Content führt zwar nicht zu einer Penalty (Abstrafung seitens Google), lässt die eigene Website aber ungepflegt wirken und kann sich nachteilig auswirken. Auerdem wird durch diese doppelten Inhalte das Crawl-Budget belastet, was bei mehreren Millionen Seiten durchaus ein Thema ist.
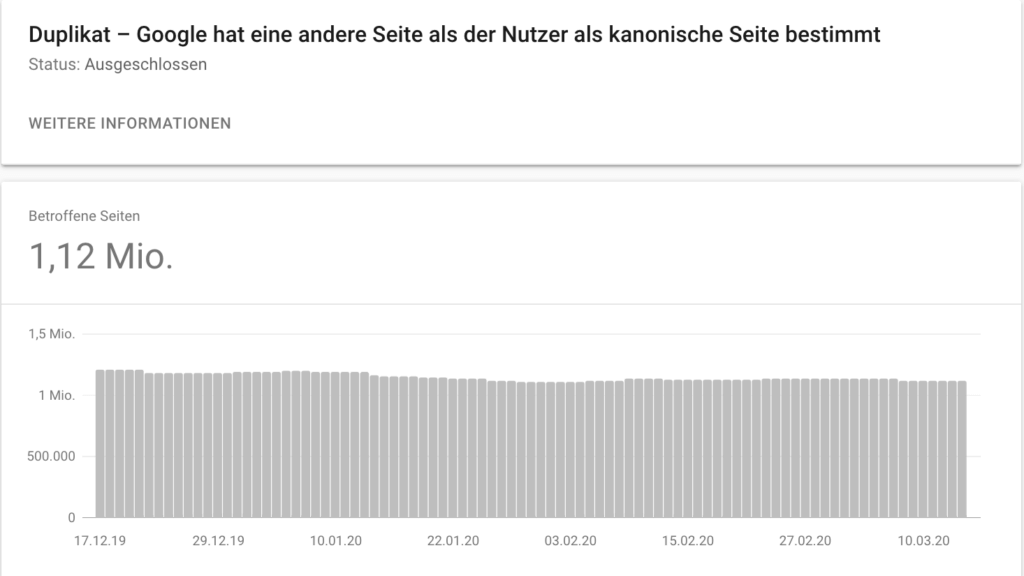
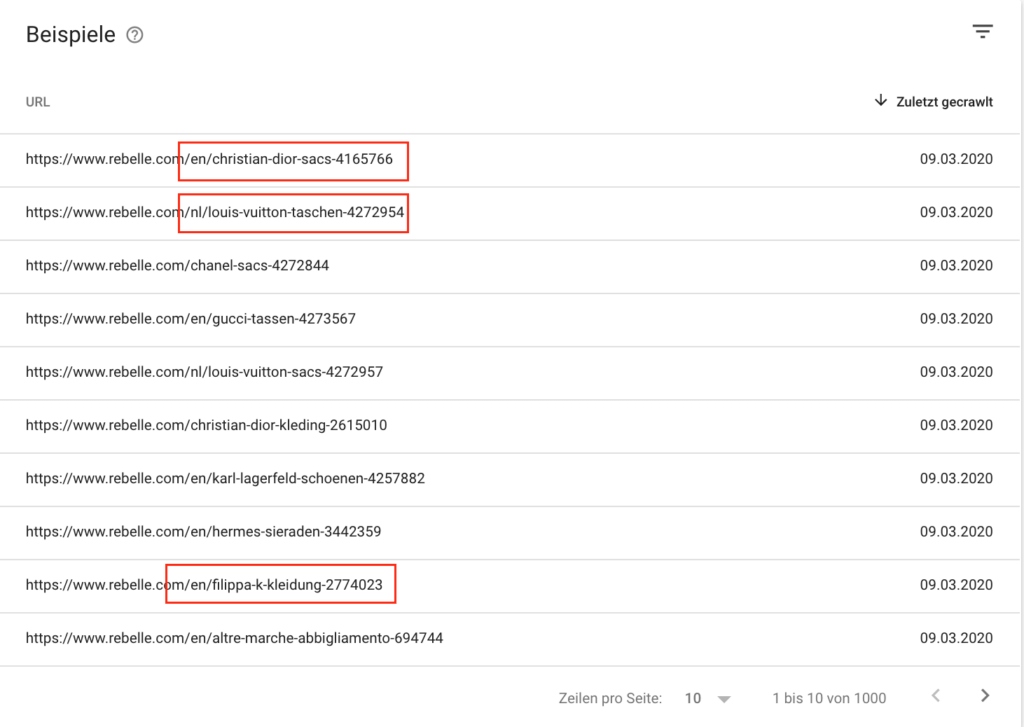

In diesem Beispiel hat Google also selbst erkannt, dass die von Rebelle gewählte kanonische URL für die niederländische Seite nl/louis-vuitton-taschen-4272954 keinen Sinn ergibt, und diese automatisch zu einer anderen URL berichtigt.
Das oben beschriebene Problem wurde unter anderem ausgelöst durch folgende Ursachen:
Ein Produkt sollte pro Sprache nur unter einer URL zu erreichen sein. Hier ein Beispiel für die Handtasche mit der Produktnummer 123, die von einem deutschen Nutzer verkauft wird und automatisch in alle Sprachen übersetzt wurde:
Original/DE: https://www.rebelle.com/de/handtaschen-123
EN: https://www.rebelle.com/en/handbags-123
FR: https://www.rebelle.com/fr/sacs-a-main-123
NL: https://www.rebelle.com/nl/handtassen-123
Allerdings finden sich in der Sitemap und im Index für dasselbe Produkt auch falsche URLs mit fehlenden Übersetzungen wieder, wie z.B.:
EN: https://www.rebelle.com/en/handtaschen-123
FR: https://www.rebelle.com/fr/handtaschen-123
NL: https://www.rebelle.com/nl/handtaschen-123
Besagte Handtasche 123 ist unter all diesen URLs zu erreichen, denn der Logik des Systems ist es egal, was vor der Nummer steht. Statt „handtaschen“ kann hier auch „abc“ stehen, nur die Nummer ist wichtig, um beim richtigen Produkt zu landen:
https://www.rebelle.com/abc-123
Hreflang-Tags zeichnen eigentlich die internationalen Versionen der gleichen Seite aus. Rebelle hat diese Tags in der Sitemap angegeben, jedoch nicht die richtigen, übersetzten URL-Versionen, sondern die falschen, wie bei Ursache 1 gezeigt:

Rebelle setzt alle Canonicals immer selbstreferenzierend ein, auch bei den falschen, nicht übersetzten URLs. Die falsche URL /nl/shoes-4199819 hat also einen Canonical, der auf sich selbst zeigt, obwohl dieser auf die ins Niederländische übersetzte URL zeigen müsste. Google erkennt, dass es hier Fehler gibt, und setzt kanonische URLs anders als vorgegeben.
Zusätzlich sind die Produktseiten wie oben schon erwähnt von kurzer Lebensdauer. Produktseiten werden erstellt und wieder abgeschaltet, das Umfeld ist hochdynamisch.
Auch das internationale Konzept mit den Übersetzungen scheint nicht zu 100 % ausgereift zu sein. Beispielsweise sind auf der italienischen Sprachversion viel mehr Seiten indexiert als in anderen Sprachen. Es ist laut Rebelle Fakt, dass auf dem italienischen Markt die meisten Produkte zum Verkauf eingestellt werden, jedoch dürfte sich die Anzahl der indexierten Seiten nicht gro unterscheiden, wenn jede Seite automatisch auch in alle anderen Sprachen übersetzt wird.
Eine URL pro Sprache durch Weiterleitungen
In jeder Sprache sollte jedes Produkt unter genau einer URL zu finden sein. Alle bestehenden falschen URLs müssen zu dieser einen übersetzten Version weitergeleitet werden, damit weder der User noch der Bot verwirrt ist. Erst wenn dieser Schritt getan ist, können die nachfolgenden Schritte angewandt werden. Auerdem muss überprüft werden, ob tatsächlich alle Seiten automatisch übersetzt werden.
Sitemaps bereinigen
Nun muss man nur noch sichergehen, dass die richtigen, vorher definierten URLs in der Sitemap vertreten sind. Jedes Produkt sollte pro Sprache nur unter der einen URL in der Sitemap sein. Dies kann man gewährleisten, indem man beispielsweise nach identischen Produktnummern sucht und die falschen Kopien löscht.
Hreflang-Tags dementsprechend richtig setzen
Wenn diese eine URL pro Produkt und Sprache bestimmt ist, kann man das Hreflang-Tag einsetzen, um Google klarzumachen, welche Seite zu welcher Sprache gehört. Dies führt unter anderem dazu, dass die richtige Seite in den richtigen Ländern/bei den richtigen Nutzern rankt, beispielsweise die französische Produktseite bei französischsprachigen Nutzern. Da Rebelle die Hreflang-Tags in der Sitemap integriert hat, müssen die Tags dort geändert werden.
Canonicals richtig verweisen
Die Canonical-Tags sollten nun, wie zuvor auch, auf sich selbst verweisen. Indem die falschen URLs jetzt eliminiert sind, sollten hier keine Fehler mehr entstehen.
Fazit: Vor allem groe Websites mit vielen Millionen Seiten brauchen eine klare Struktur und ein Management des Crawl-Budgets. Duplicate Content gilt es dabei unbedingt zu vermeiden, beim Einsatz von Virtual Page Views ist das Fehlerrisiko besonders hoch. Durch den richtigen Einsatz von Virtual Page Views, Sitemaps, Hreflang-Tags und Canonical-Tags kann Duplicate Content verhindert und das Crawl-Budget geschont werden.

